
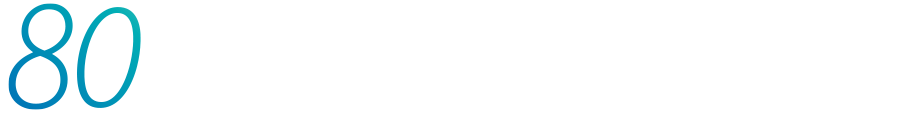



Dette presset er blant annet formulert i Digitaliserings- og forvaltningsministerens mål om 80 prosent bruk av KI i offentlig sektor innen 2025.[1] Denne artikkelen belyser rettslige og praktiske utfordringer ved bruk av KI i offentlig sektor knyttet til personvernregelverket, med særlig fokus på risikoen ved ukritisk bruk av språkmodeller i offentlig forvaltning.
Innledning
Utviklingen innenfor kunstig intelligens skjer i et raskt tempo som utfordrer de tradisjonelle rammene for kommunal forvaltning. I Tromsø kommune våren 2025 skjedde den første store skandalen knyttet til bruk av KI i offentlig sektor i Norge.
Avisen iTromsø avslørte at en rapport utarbeidet av administrasjonen i Tromsø kommune om skolestruktur hadde oppgitte kilder til skoleforskning som ikke eksisterte.[2] Hendelsen resulterte i en ekstern granskning til 1,2 millioner kroner samt forsinkelse av den politiske behandlingen av skolestruktursaken.[3]
I begynnelsen av 2026 kom et annet eksempel. Aurskog-Høland kommune brukte en språkmodell for å spare tid i opprydningen av feilfakturering av vannavgift. Det førte til at flere barn feilaktig fikk tilsendt brev med krav om å betale vannavgift.[4] En rekke ansatte i kommunen måtte jobbe ekstra for å ta unna henvendelser etter den nye feilfaktureringen.
Disse hendelsene burde fungere som en vekker for offentlig sektor.
Disse hendelsene burde fungere som en vekker for offentlig sektor. KI bør ikke implementeres kun for teknologiens skyld eller før organisasjonen er moden for det. Teknologien er et verktøy som må være rettet mot å løse et spesifikt, kartlagt problem. Videre må risikoen ved implementeringen klarlegges før KI-verktøy tas i bruk innad i en organisasjon. Kun etter det, kan kommuner ha et tilstrekkelig grunnlag til å veie fordeler ved bruken opp mot ulemper og risiko.
Fra ekspertsystemer til maskinlæring
For å forstå risikoen knyttet til å bruke KI-verktøy i kommunal saksbehandling, må vi forstå den underliggende teknologien. Kunstig intelligens som begrep ble etablert allerede på 1950-tallet.[5] Ideen har hele tiden vært den samme: Hvordan kan man få en maskin til å løse et problem som vanligvis krever menneskelig intelligens og kognisjon å løse.
Fra 1950-tallet til omtrent midten av 1990-tallet prøvde man i all hovedsak å få maskinen til å løse problemet gjennom det som ble kalt ekspertsystemer. Ekspertsystemene besto av forhåndsprogrammerte regler definert av eksperter som ble brukt for å løse et problem på et gitt samfunnsområde. I dag består de fleste KI-verktøyene av språkmodeller som er en type maskinlæring.
Maskinlæring består enkelt forklart av algoritmer som kjenner igjen mønstre i store mengder data. Målet er å få en algoritme – som er et sett med instruksjoner – til å kjenne igjen mønstre i data som den trenes på.
En algoritme som kan kjenne igjen mønstre i dataene den er trent på, kalles en maskinlæringsmodell. Målet med denne modellen, er at den kan kjenne igjen mønstre i data den ikke har blitt trent på, ukjente data. Denne trente modellen brukes deretter til å løse et problem i de ukjente dataene. I store språkmodeller kjenner den trente modellen igjen mønstre i tekst.
De dominerende verktøyene som i dag brukes som kontorstøttesystemer og skriveverktøy er store språkmodeller (Large Language Models LLMs), slik som ChatGPT. ChatGPT, Microsoft Copilot og andre språkmodeller bygger alle på underliggende GPT-teknologi.
ChatGPT heter det fordi man kan chatte med modellene. Modellen er bygget inn i et overordnet system med et brukergrensesnitt og fastsatte grenser for hvilken tekst den kan generere. Den underliggende modellen i dette systemet, er en GPT-modell.
GPT står for: Generative Pre-trained Transformer. Modellen er generativ fordi den kan produsere ny tekst basert på instruksjoner. Videre er denne tekstgenereringen pre-trained, den er forhåndstrent. Til slutt står T-en for Transformer fordi disse modellene består av en underliggende modellarkitektur som kalles transformermodeller.
Forhåndstreningen til modellen har skjedd ved at utviklerne av GPT-modellene har skrapet internett for store mengder tekst. OpenAI, selskapet bak ChatGPT, trente den underliggende modellen på tekst fra flere millioner åpne nettsider i 2019. Webskraperoboter har gått inn på åpne nettsider, kopiert innholdet og lastet det ned i en database. Utviklerne av språkmodellen har deretter brukt dette tekstkorpuset for å trene modellene. Denne teksten har gjort forhåndstreningen mulig.
Overforenklet, regner språkmodellen ut sannsynligheten av hva som er et passende ord i en setning basert på konteksten setningen kommer frem i. Når setningen er skrapet fra internett, vet man hva som er et passende ord i den gitte konteksten. Modellen kan da tilpasses konteksten.
Tenk for eksempel på følgende setning:
Jeg er [...]. |
Det mest passende ordet i slutten av denne setningen vil være avhengig av den forrige setningen, men også muligens et ord 16 ord før setningen. Språkmodellen regner ut om det mest sannsynlige ordet i denne setningen for eksempel er “sulten”, “tørst” eller “ansatt i kommunal sektor” basert på konteksten til setningen.
Siden det riktige ordet er kjent i teksten skrapet fra internett, kan man fjerne det siste ordet i setningen under forhåndstreningen. Sannsynligheten for at et ord etterfølger et annet i en setning kan dermed tilpasses, siden man vet hva det “riktige” siste ordet er i akkurat den setningen. Denne forhåndstreningen muliggjør generering av ny tekst etter en instruksjon når forhåndstreningen er ferdig, og språkmodellen benyttes til å generere innhold på ny, ukjent data.
Denne forhåndstreningen muliggjør generering av ny tekst etter en instruksjon når forhåndstreningen er ferdig, og språkmodellen benyttes til å generere innhold på ny, ukjent data.
Det er avgjørende for å bruke språkmodellene på en effektiv måte å erkjenne at disse modellene ikke opererer med "sannhet" eller “riktighet”, men regner ut det mest sannsynlige neste ordet i en setning basert på mønstergjenkjenning i språk fra forhåndstreningen. Dette medfører en iboende risiko for hallusinering.
Dette medfører en iboende risiko for hallusinering.
Hallusinering er de tilfellene hvor språkmodellen dikter opp informasjon – slik man så i Tromsø-saken der systemet genererte falsk skoleforskning. I tilfellet i skolestrukturapporten i Tromsø, genererte språkmodellen oppdiktet skoleforskning, men av ekte skoleforskere. I det tilfellet ble dermed personopplysninger behandlet i språkmodellen.
Det fremheves ofte at det haster med å regulere KI. I den sammenheng blir ofte nye regler fra EU, EUs AI Act trukket frem.[6] AI-forordningen, som er varslet å bli en del av EØS-avtalen, og som regjeringen tar sikte på å inkorporere i norsk rett så snart som mulig, er viktig for å håndtere den iboende risikoen til KI.
Samtidig vil bruk av KI-systemer allerede være underlagt en rekke eksisterende regelsett. Når det brukes i saksbehandling, vil man eksempelvis måtte etterleve forvaltningslovens krav og eventuelt sektorspesifikt regelverk. Videre må behandling av personopplysninger i KI-verktøy etterleve kravene i personopplysningsloven og personvernforordningen (personvernregelverket).
Rettslig grunnlag for behandling av personopplysninger i KI-systemer
All bruk av KI som involverer personopplysninger – definert som informasjon som kan identifisere en fysisk person – vil kunne komme inn under virkeområdet til personvernregelverket. Personvernregelverket er langt og detaljert. Personvernforordningen inneholder for eksempel 99 artikler og 173 fortalepunkter som artiklene må tolkes i samsvar med. Videre må dette regelverket også tolkes i tråd med praksis fra EU-domstolen. I det følgende vil derfor kun et av de viktigste kravene i personvernregelverket gjennomgås – kravet til behandlingsgrunnlag.
All bruk av KI som involverer personopplysninger – definert som informasjon som kan identifisere en fysisk person – vil kunne komme inn under virkeområdet til personvernregelverket.
For at en behandlingsansvarlig, for eksempel en kommune, lovlig skal kunne behandle personopplysninger om innbyggere, ansatte eller skoleforskere, må kommunen ha et behandlingsgrunnlag i personvernforordningen artikkel 6.
Behandlingsgrunnlag kan sammenlignes med en hjemmel for å behandle personopplysninger. Hvis ikke den behandlingsansvarlige har et gyldig behandlingsgrunnlag i personvernforordningen, er ikke behandlingen lovlig.
Personvernforordningen inneholder seks alternative behandlingsgrunnlag i artikkel 6 nr. 1 bokstav a) til f):
Artikkel 6 nr. 1 bokstav a): |
Samtykke |
Artikkel 6 nr. 1 bokstav b): |
Kontrakt |
Artikkel 6 nr. 1 bokstav c): |
Rettslig forpliktelse |
Artikkel 6 nr. 1 bokstav d): |
Vitale interesser |
Artikkel 6 nr. 1 bokstav e): |
Oppgave i allmennhetens interesse eller utøvelse av offentlig myndighet |
Artikkel 6 nr. 1 bokstav f): |
Berettigede interesser |
Personvernforordningen er generell og gjelder både for offentlige myndigheter og private som behandler personopplysninger. Det følger direkte av artikkel 6 andre ledd at offentlige myndigheter ikke kan benytte artikkel 6 nr. 1 bokstav f). Dette siste behandlingsgrunnlaget er derfor ikke aktuelt for kommunal sektor.
Vitale interesser i artikkel 6 nr. 1 bokstav d) knytter seg tett til en persons overlevelse. En typisk behandling av personopplysninger etter dette grunnlaget, vil være hvis en person er bevisstløs og dermed ikke kan samtykke. Det er sjelden en aktuell situasjon ved behandling av personopplysninger i KI-verktøy i kommunal saksbehandling.
For at behandlingsgrunnlaget “kontrakt” i personvernforordningen artikkel 6 nr. 1 bokstav b) skal være et lovlig behandlingsgrunnlag for behandling i et KI-verktøy, må det være objektivt sett strengt nødvendig å behandle personopplysninger i et KI-verktøy for hovedformålet med kontrakten. Det vil sjelden være situasjonen for en kommune.
Samtykke i personvernforordningen artikkel 6 nr. 1 bokstav a) er sjelden et lovlig behandlingsgrunnlag for offentlige myndigheter, jf. fortalepunkt nr. 43 til personvernforordningen. Det er fordi et samtykke må være reelt frivillig, og det er sjelden tilfellet når det er en klar maktforskjell mellom den behandlingsansvarlige og den personopplysningen tilhører, den registrerte.
De resterende relevante behandlingsgrunnlagene er dermed artikkel 6 nr. 1 bokstav c) og e), rettslig forpliktelse og utøvelse av offentlig myndighet. For behandlingsgrunnlaget i bokstav c) må kommunen være forpliktet i lov eller forskrift å behandle personopplysninger i et KI-verktøy for at det skal være lovlig. Det vil sjelden være tilfellet.
Det er dermed behandlingsgrunnlaget i artikkel 6 nr. 1 bokstav e) som fremstår som det aktuelle behandlingsgrunnlaget for behandling av personopplysninger i et KI-verktøy av en kommune.
Det er dermed behandlingsgrunnlaget i artikkel 6 nr. 1 bokstav e) som fremstår som det aktuelle behandlingsgrunnlaget for behandling av personopplysninger i et KI-verktøy av en kommune.
Et behandlingsgrunnlag etter artikkel 6 nr. 1 bokstav e) trenger det som kalles et supplerende rettsgrunnlag etter nasjonal rett, jf. personvernforordningen artikkel 6 nr. 3. Det betyr at det må komme frem av en norsk lov eller forskrift at kommunen kan behandle personopplysninger for et gitt formål for at det skal være lovlig etter bokstav e). I forarbeidene til personopplysningsloven som gjennomfører personvernforordningen i norsk rett kommer følgende frem om kravet til det supplerende rettsgrunnlaget:
“Dersom behandlingen av personopplysninger utgjør et inngrep i retten til privatliv etter Grunnloven § 102 eller EMK artikkel 8, kan det imidlertid være nødvendig med et mer spesifikt rettslig grunnlag for behandlingen enn det ordlyden i forordningen kan tilsi. Det følger også uttrykkelig av fortalepunkt 41 at et rettslig grunnlag bør være «tydelig og presist, og anvendelsen av det bør være forutsigbar for personer som omfattes av det, i samsvar med rettspraksisen til Den europeiske unions domstol («Domstolen») og Den europeiske menneskerettighetsdomstol». Med andre ord må forordningens krav om supplerende rettsgrunnlag for behandlingen tolkes og anvendes i tråd med de menneskerettslige kravene til rettsgrunnlag for inngrep i retten til privatliv. Dette innebærer at det må foretas en nærmere vurdering av rettsgrunnlaget og behandlingen, hvor det blant annet må legges vekt på hvor inngripende behandlingen er. Etter omstendighetene kan utfallet av en slik vurdering bli at det kreves et mer spesifikt grunnlag enn det som kan synes å være minimumskravene etter ordlyden i forordningen”.[7]
Personvernforordningen stiller krav om et forutberegnelig og tydelig rettsgrunnlag etter nasjonal rett. En inngripende form for behandling av personopplysninger som utgjør et inngrep i retten til privatliv, vil kreve et enda klarere og spesifikt rettsgrunnlag i en norsk lov eller forskrift.
Dersom en kommune skal behandle innbyggernes eller de ansattes personopplysninger i et KI-verktøy til et inngripende formål eller til et formål som i realiteten innebærer myndighetsutøvelse, vil personvernforordningen og menneskerettighetene ofte stille krav til at det må fremgå klart av lov eller forskrift.
Manglende behandlingsgrunnlag regnes som et mer alvorlig brudd på personvernregelverket enn andre brudd på regelverket.
Manglende behandlingsgrunnlag regnes som et mer alvorlig brudd på personvernregelverket enn andre brudd på regelverket. Det kan leses ut av at manglende behandlingsgrunnlag sanksjoneres med en høyere bøtesats i personvernforordningen artikkel 83 nr. 5.
Risiko og sikkerhet knyttet til bruk av KI-verktøy i kommuner
Implementering av KI-verktøy i en kommune innebærer flere risikofaktorer utover de rent juridiske. Kommuner vil komme opp i dilemmaer der jussen ikke gir entydig konklusjoner og der kommunen må avveie flere hensyn mot hverandre.
Et eksempel på et slikt dilemma er hvis en kommune vil kutte kostnader knyttet til journalføring og arkivering. Kommunen tar i bruk sensitivitetsanalyse for å vurdere fulltekstpublisering av inngående dokumenter.[8] Tenk hvis kommunen ønsker å helautomatisere journalføringen i postjournalen. Kommunen vet at den underliggende KI-teknologien vil gjøre feil i omtrent 1 av 50 tilfeller. Er det akseptabelt å bruke KI til analyse av inngående dokumenter hvis modellen gjør feil i 2 prosent av tilfellene slik som i dette eksemplet? En slik feilrate kan føre til ulovlig publisering av taushetsbelagt informasjon. Samtidig kan og vil menneskelige saksbehandlere også kunne gjøre feil.
Et annet dilemma kommuner og andre arbeidsgivere står i knytter seg til skyggebruk.[9] Hvis kommunen ikke tilbyr trygge KI-verktøy, vil ansatte ofte ta i bruk KI-verktøy utenfor arbeidsgivers kontroll for å effektivisere egen arbeidshverdag. Hvis verktøyene arbeidsgiveren tilbyr er langt dårligere enn det som er åpent tilgjengelig og gratis på internett, er det også en risiko for slik skyggebruk.
Skyggebruk er et reelt dilemma der kommuner og andre arbeidsgivere må foreta et valg mellom bruk innenfor trygge rammer kontra helt ukontrollert bruk. Dilemmaet kan også løses på andre måter, slik som å sperre tilganger til store utrygge språkmodeller via kommunes internettløsning.
Videre inneholder et mål om 80 prosent bruk av KI-verktøy i offentlig sektor også sikkerhetsmessige utfordringer. Vi lever i den mest usikre sikkerhetspolitiske situasjonen siden andre verdenskrig.[10] Store språkmodeller benytter i stor grad "global processing chains", som betyr at norske personopplysninger og data om norsk samfunnskritisk infrastruktur kan bli behandlet i land utenfor EØS, inkludert USA.
Lovligheten av slike overførsler av personopplysninger til USA hviler i dag på et usikkert juridisk grunnlag som tidligere har blitt kjent ugyldig to ganger av EU-domstolen, med en risiko for å bli underkjent i fremtiden. I den mest usikre sikkerhetspolitiske situasjonen siden andre verdenskrig burde kommuner, som er ansvarlig for mye kritisk infrastruktur, gjøre grundige risikovurderinger av effektiviseringsgevinsten av bruk av KI-verktøy.
Slike risikovurderinger burde også hensynta slike sikkerhetsaspekter. Når NIS 2-direktivet blir inkorporert i norsk rett, vil en rekke kommuner og kommunale foretak bli lovpålagt å gjøre slike risikovurderinger. Derfor kan det være hensiktsmessig å komme i gang med slike risikovurderinger allerede i dag.
Avslutning
KI kan være et effektivt verktøy, men kan aldri fullt ut erstatte den faglige skjønnsutøvelsen i kommunal forvaltning. For kontrollutvalgene blir det i tiden fremover en hovedoppgave å påse at digitaliseringen ikke skjer på bekostning av rettssikkerhet eller innbyggernes personvern.
For kontrollutvalgene blir det i tiden fremover en hovedoppgave å påse at digitaliseringen ikke skjer på bekostning av rettssikkerhet eller innbyggernes personvern.
Et strategisk valg for kontrollutvalg vil kunne være å være noe mer proaktiv i kontrollen. Det kan eksempelvis gjøres ved å forespørre kommunene om hvordan de håndterer KI-risikoen på ledernivå allerede før skandalen kommer.
Avslutningsvis gjentas et av de viktigste poengene KI-skandalen i Tromsø burde lære oss: Aldri stol blindt på en språkmodell hvis du ikke selv behersker fagfeltet godt nok til å se når den tar feil. Hvis man stoler blindt på slike språkmodeller, er det en risiko for oppdiktet skoleforskning og fakturering av vannavgift til barn.
_______________________________________________
Noter:
[1] Se ytterligere, NRK, Regjeringen ber 80 prosent av offentlig sektor bruke KI innen 2025. Tilgjengelig på: Regjeringen vil at 80 prosent av offentlig sektor bruker KI: – Urealistisk, mener KI-forsker – NRK Norge – Oversikt over nyheter fra ulike deler av landet.
[2] Se ytterligere iTromsø, – Den første store KI-skandalen i norsk offentlig sektor. Tilgjengelig på: – Den første store KI-skandalen i norsk offentlig sektor - itromso.no.
[3] Se Kommunal Rapport, Granskning av KI-skandalen i Tromsø koster 1,2 millioner Tilgjengelig på: Granskning av KI-skandalen i Tromsø koster 1,2 millioner.
[4] Aftenposten, KI-tabbe i Aurskog-Høland – barn fikk vannregninger. Tilgjengelig på: Kommune med KI-tabbe: Sendte vannregninger til barn.
[5] Se Alan Turing (1950), Computing Machinery and intelligence. Mind 433-460.
[6] Regulation (EU) 2024/1689 of the European Parliament and of the Council of 13 June 2024 laying down harmonised rules on artificial intelligence and amending Regulations (EC) No 300/2008, (EU) No 167/2013, (EU) No 168/2013, (EU) 2018/858, (EU) 2018/1139 and (EU) 2019/2144 and Directives 2014/90/EU, (EU) 2016/797 and (EU) 2020/1828 (Artificial Intelligence Act) OJ L 2024/1689.
[7] Prop. 56 LS (2017–2018) Lov om behandling av personopplysninger (personopplysningsloven) og samtykke til deltakelse i en beslutning i EØS-komiteen om innlemmelse av forordning (EU) nr. 2016/679 (generell personvernforordning) i EØS-avtalen side 33.
[8] Se for eksempel, Computerworld, Bruker KI til fulltekstpublisering av postjournal. Tilgjengelig på: Bruker KI til fulltekstpublisering av postjournal
[9] Se for eksempel Computerworld, Skygge-AI: Når kunstig intelligens blir en tikkende bombe under virksomhetens data. Tilgjengelig på: Skygge-AI: Når kunstig intelligens blir en tikkende bombe under virksomhetens data.
[10]
Se, Regjeringen, utenrikspolitisk redegjørelse 2025. Tilgjengelig på: Utenrikspolitisk redegjørelse 8. april - regjeringen.no
__________________________________
Bjørn Aslak Juliussen er jurist og har doktorgrad i informatikk om kunstig intelligens og personvern. Han er tilknyttet UiT Norges arktiske universitet og er medlem av personvernnemnda for perioden 2025 – 2028. Han har gitt ut to bøker: En introduksjon til personvernregelverket og en bok om hvordan regelverksetterlevelse kan bygges inn i kunstig intelligente systemer. Videre har han publisert en rekke vitenskapelige artikler på norsk og engelsk om personvern og kunstig intelligens.
Denne artikkelen er basert på et foredrag Juliussen holdt på NKRFs Kontrollutvalgskonferanse 2026 28. januar med tittel: “Kunstig intelligens og personvern – Nåværende og fremtidige utfordringer for kommunale kontrollutvalg”.
Lenke til kontroll & revisjon nr. 3/2026: